

Researchers and students are more and more interested in the use of text- and data-mining (TDM) for studying large quantities of digitally available text corpora, such as newspapers and journals. With TDM you can systematically experiment on and query sources as newspapers and periodicals in bulk, so that you can discover the evolution of concepts or examine relationships between text corpora. This allows you to answer research questions that were hitherto out of scope. Through this showcase, the Digital Humanities Team at Utrecht University Library shows how to search various text corpora step by step using I-Analyzer.
Text mining with I-Analyzer
The I-Analyzer developed by the Digital Humanities Lab at the Centre for Digital Humanities, is an online text- and data-mining application and designed to experiment with TDM for the first time. In the I-Analyzer you can access the readily available corpuses provided by the Utrecht University Library, and more. Examples of these corpuses are historical newspaper collections such as Delpher (Dutch newspapers), The Guardian-Observer and The Times, and ECCO (Eighteenth Century Collections Online). Additionally, the I-Analyzer provides simple visualisations of the search results, such as a word frequency generator and bar graphs. You can also download your search results for more advanced analysis.
What you can do with the I-Analyzer?

Historical newspapers provide a rich insight into the past, yet researchers rarely have time to browse issues of one newspaper, let alone to compare newspapers with each other. With the I-Analyzer you can do just that. Let’s say you are interested in mid-nineteenth upheavals that occurred across Europe. Did newspapers report on these, and if so, on which revolutions did they report? By systematically searching for the keyword ‘revolution’, we can compare different newspapers, to examine if press coverage, and potentially information flows, were different between newspapers and countries.
Systematically searching revolutions in Europe, how does this work?
Using this specific case study we’ll demonstrate how to search various corpora step by step with the I-Analyzer. You could select the corpora of both Delpher and The Times in the I-Analyzer to retrieve relevant articles from this period. You may also want to incorporate external corpora from Gallica, the digital library of the Bibliothèque Nationale de France (BnF), but unfortunately bulk downloads of these search results are currently difficult to obtain. However, the Centre for Digital Humanities is looking into the possibility of incorporating portions of Gallica’s vast corpuses into the I-Analyzer, so keep an eye out for this development!

After retrieving all the articles mentioning ‘revolution’ from the corpuses, you can download the search results from each corpora to plot the locations of the nineteenth-century revolutions onto a map. Some experience with R or Python is beneficial at this point, but if you have limited to no coding skills the same results can certainly be achieved by consulting a data engineer. The full workflow and code are available here.
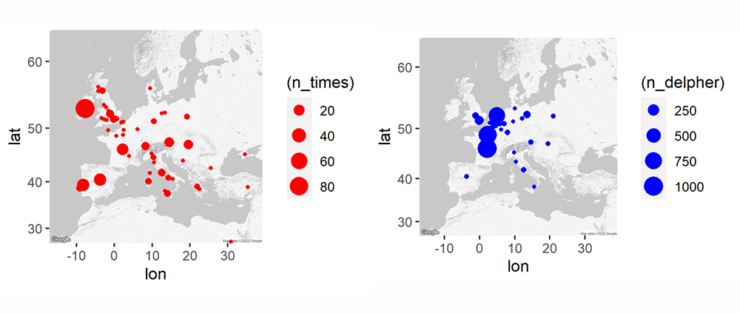
Maps of Europe
The results are two maps of Europe: one for the Delpher newspapers and one for The Times, where the size of the dots correspond to the number of times each placename was mentioned in article titles between 1840 and 1860. Looking at the maps, it is clear that Paris and France dominated when it came to revolutions during this period, but there is also a lot of activity in central and eastern Europe, as well as northern Europe. Only Scandinavian countries, apart from Denmark, seems to have avoided revolutions. These results seem to accurately reflect the political and social upheaval that was occurring in these regions at the time. Likely starting with France in 1848, revolutions spread throughout Europe, as far as Turkey and possibly Egypt. Perhaps this TDM approach even allows to discover ‘new’ revolutions that are up to now poorly documented. Interestingly, The Times seems to have covered more distinct revolutions than Dutch newspapers.
Digital Humanities Support
The I-Analyzer is one way the Centre for Digital Humanities and the Utrecht University Library support researchers and students in systematically studying the archives of our newspaper and periodical collections. Our goal is to continue to add more of the Library’s corpora to the I-Analyzer, including the library’s Special Collections. Opening up our collections for study and enquiry aligns with the library’s and the wider UU community’s ambition to support Open Science and FAIR data practices.
Workshop: Working with large text corpora in I-Analyzer
If you want to learn how to use the I-Analyzer yourself and see how we made these maps, register for the I-Analyzer workshop on October 4th!
This article was originally published here at uu.nl.